內省
使用 Prisma ORM 內省您的資料庫
在本指南中,我們將使用包含三個表格的示範 SQL schema
CREATE TABLE `Post` (
`id` int NOT NULL AUTO_INCREMENT,
`createdAt` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
`updatedAt` datetime(3) NOT NULL,
`title` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`content` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`published` tinyint(1) NOT NULL DEFAULT '0',
`authorId` int NOT NULL,
PRIMARY KEY (`id`),
KEY `Post_authorId_idx` (`authorId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `Profile` (
`id` int NOT NULL AUTO_INCREMENT,
`bio` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`userId` int NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `Profile_userId_key` (`userId`),
KEY `Profile_userId_idx` (`userId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `User` (
`id` int NOT NULL AUTO_INCREMENT,
`email` varchar(191) COLLATE utf8mb4_unicode_ci NOT NULL,
`name` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `User_email_key` (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
展開以查看表格的圖形化概覽
Post
| 欄位名稱 | 類型 | 主鍵 | 外鍵 | 必填 | 預設值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自動遞增 |
createdAt | datetime(3) | 否 | 否 | ✔️ | now() |
updatedAt | datetime(3) | 否 | 否 | ✔️ | |
title | varchar(255) | 否 | 否 | ✔️ | - |
content | varchar(191) | 否 | 否 | 否 | - |
published | tinyint(1) | 否 | 否 | ✔️ | false |
authorId | int | 否 | 否 | ✔️ | - |
Profile
| 欄位名稱 | 類型 | 主鍵 | 外鍵 | 必填 | 預設值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自動遞增 |
bio | varchar(191) | 否 | 否 | 否 | - |
userId | int | 否 | 否 | ✔️ | - |
User
| 欄位名稱 | 類型 | 主鍵 | 外鍵 | 必填 | 預設值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自動遞增 |
name | varchar(191) | 否 | 否 | 否 | - |
email | varchar(191) | 否 | 否 | ✔️ | - |
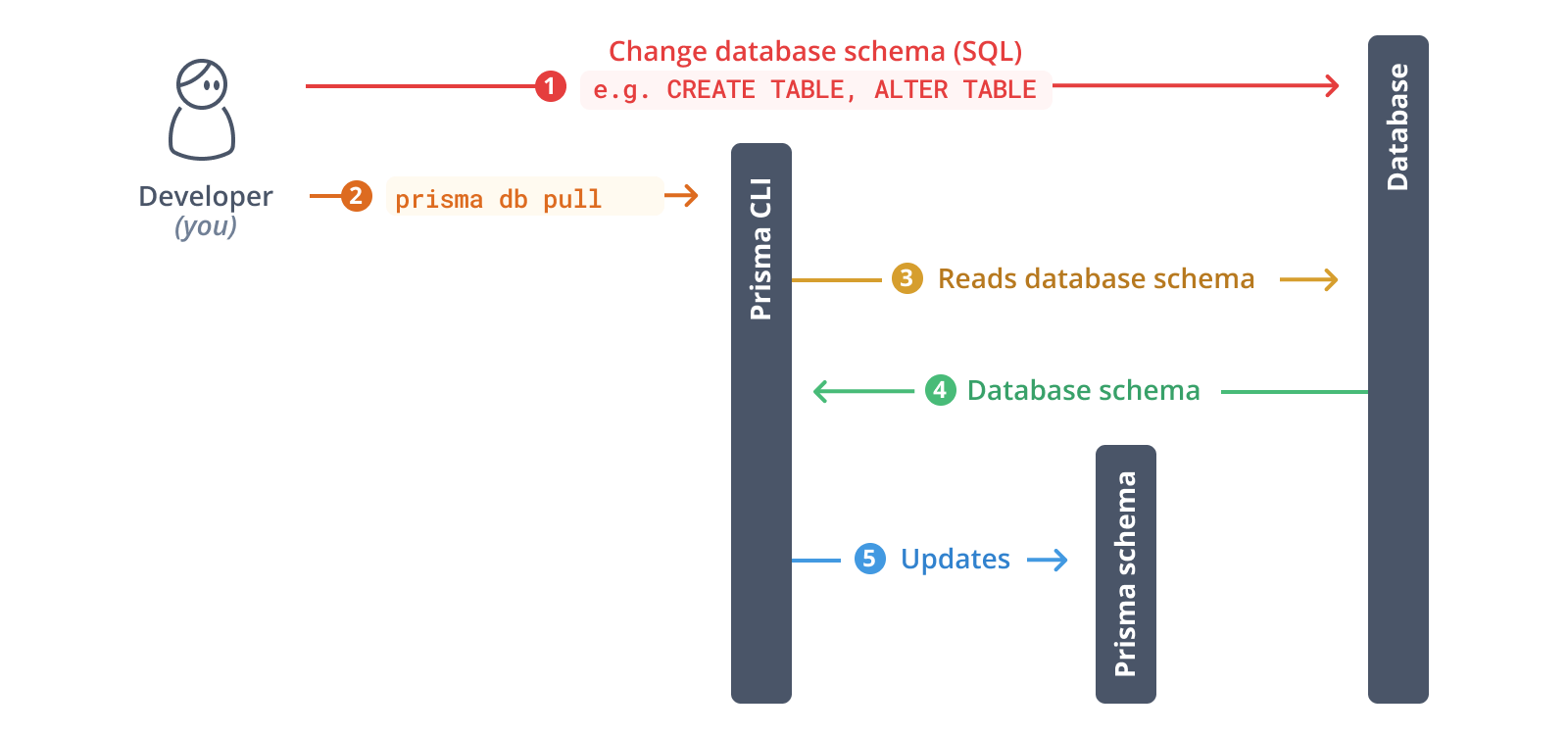
下一步,您將內省您的資料庫。內省的結果將是 Prisma schema 內的資料模型。
執行以下命令以內省您的資料庫
npx prisma db pull
此命令會讀取在 .env 中定義的 DATABASE_URL 環境變數,並連接到您的資料庫。連線建立後,它會內省資料庫(即讀取資料庫 schema)。然後,它會將資料庫 schema 從 SQL 轉換為 Prisma 資料模型。
內省完成後,您的 Prisma schema 將會更新
資料模型現在看起來與此類似
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime
title String @db.VarChar(255)
content String?
published Boolean @default(false)
authorId Int
@@index([authorId])
}
model Profile {
id Int @id @default(autoincrement())
bio String?
userId Int @unique
@@index([userId])
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
有關 schema 定義的詳細資訊,請參閱 Prisma schema 參考。
Prisma 的資料模型是您的資料庫 schema 的宣告式表示,並且是產生的 Prisma Client 程式庫的基礎。您的 Prisma Client 實例將公開針對這些模型量身定制的查詢。
然後,您需要使用關聯欄位在您的資料之間新增任何遺失的關聯
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime
title String @db.VarChar(255)
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
@@index([authorId])
}
model Profile {
id Int @id @default(autoincrement())
bio String?
user User @relation(fields: [userId], references: [id])
userId Int @unique
@@index([userId])
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
profile Profile?
}
在此之後,第二次在您的資料庫上執行內省
npx prisma db pull
Prisma Migrate 現在將保留手動新增的關聯欄位。
由於關聯欄位是虛擬的(即它們不會直接在資料庫中顯現),您可以手動重新命名 Prisma schema 中的關聯欄位,而無需觸及資料庫。
在此範例中,資料庫 schema 遵循 Prisma ORM 模型的命名慣例。這優化了產生的 Prisma Client API 的人體工學。
使用自訂模型和欄位名稱
但有時,您可能想要對 Prisma Client API 中公開的欄位和表格名稱進行其他變更。一個常見的範例是轉換資料庫 schema 中常用的snake_case表示法,轉換為對於 JavaScript/TypeScript 開發人員來說感覺更自然的PascalCase和camelCase表示法。
假設您從內省中獲得了以下基於 snake_case 表示法的模型
model my_user {
user_id Int @id @default(autoincrement())
first_name String?
last_name String @unique
}
如果您為此模型產生 Prisma Client API,它將在 API 中採用 snake_case 表示法
const user = await prisma.my_user.create({
data: {
first_name: 'Alice',
last_name: 'Smith',
},
})
如果您不想在 Prisma Client API 中使用資料庫中的表格和欄位名稱,您可以使用 @map 和 @@map 來配置它們
model MyUser {
userId Int @id @default(autoincrement()) @map("user_id")
firstName String? @map("first_name")
lastName String @unique @map("last_name")
@@map("my_user")
}
透過這種方法,您可以隨意命名您的模型及其欄位,並使用 @map(用於欄位名稱)和 @@map(用於模型名稱)指向底層的表格和欄位。您的 Prisma Client API 現在看起來如下
const user = await prisma.myUser.create({
data: {
firstName: 'Alice',
lastName: 'Smith',
},
})
在配置您的 Prisma Client API頁面上了解更多資訊。