Prisma ORM 是 ORM 嗎?
簡短回答這個問題:是的,Prisma ORM 是一種新型的 ORM,它與傳統 ORM 截然不同,並且沒有傳統 ORM 常見的許多問題。
傳統 ORM 提供了一種物件導向的方式來處理關聯式資料庫,方法是將資料表對應到您程式語言中的模型類別。這種方法導致許多問題,這些問題是由物件關聯阻抗失配所引起的。
Prisma ORM 的運作方式與此截然不同。使用 Prisma ORM,您可以在宣告式的 Prisma schema 中定義您的模型,該 schema 作為您的資料庫結構描述和程式語言中模型的單一事實來源。在您的應用程式程式碼中,您可以接著使用 Prisma Client 以型別安全的方式讀取和寫入資料庫中的資料,而無需管理複雜模型實例的額外負擔。這使得查詢資料的過程更加自然且更可預測,因為 Prisma Client 始終返回純 JavaScript 物件。
在本文中,您將更詳細地了解 ORM 模式和工作流程、Prisma ORM 如何實作資料映射器模式,以及 Prisma ORM 方法的優點。
什麼是 ORM?
如果您已經熟悉 ORM,請隨時跳到關於 Prisma ORM 的下一節。
ORM 模式 - 活動記錄和資料映射器
ORM 提供高階資料庫抽象化。它們透過物件公開程式化介面,以建立、讀取、刪除和操作資料,同時隱藏資料庫的一些複雜性。
ORM 的概念是將您的模型定義為對應到資料庫中資料表的 類別。類別及其例項為您提供程式化 API,以讀取和寫入資料庫中的資料。
有兩種常見的 ORM 模式:活動記錄和資料映射器,它們在物件和資料庫之間傳輸資料的方式上有所不同。雖然這兩種模式都要求您將類別定義為主要建構區塊,但兩者之間最顯著的區別在於,資料映射器模式將應用程式程式碼中的記憶體內物件與資料庫分離,並使用資料映射器層在兩者之間傳輸資料。實際上,這表示使用資料映射器時,記憶體內物件(代表資料庫中的資料)甚至不知道資料庫的存在。
活動記錄
活動記錄 ORM 將模型類別對應到資料庫資料表,其中兩種表示形式的結構密切相關,例如,模型類別中的每個欄位在資料庫資料表中都會有一個相符的資料行。模型類別的例項包裝資料庫列,並攜帶資料和存取邏輯來處理資料庫中持久性的變更。此外,模型類別可以攜帶特定於模型中資料的業務邏輯。
模型類別通常具有執行以下操作的方法
- 從 SQL 查詢建構模型例項。
- 建構新的例項,以便稍後插入到資料表中。
- 包裝常用的 SQL 查詢並傳回活動記錄物件。
- 更新資料庫並將活動記錄中的資料插入其中。
- 取得和設定欄位。
- 實作業務邏輯。
資料映射器
與活動記錄相反,資料映射器 ORM 將應用程式的資料記憶體內表示形式與資料庫的表示形式分離。透過要求您將對應責任分離為兩種類型的類別來實現分離
- 實體類別:應用程式的實體記憶體內表示形式,它不知道資料庫的存在
- 映射器類別:這些類別有兩個職責
- 在兩種表示形式之間轉換資料。
- 產生從資料庫擷取資料和在資料庫中持久性變更所需的 SQL。
資料映射器 ORM 允許在程式碼中實作的問題領域與資料庫之間具有更大的彈性。這是因為資料映射器模式允許您隱藏資料庫的實作方式,這不是思考整個資料映射層後面的領域的理想方式。
傳統資料映射器 ORM 執行此操作的原因之一是組織結構,其中兩個職責將由不同的團隊處理,例如,DBA 和後端開發人員。
實際上,並非所有資料映射器 ORM 都嚴格遵守此模式。例如,TypeORM,TypeScript 生態系統中流行的 ORM,它同時支援活動記錄和資料映射器,它採用以下資料映射器方法
- 實體類別使用裝飾器 (
@Column) 將類別屬性對應到資料表資料行,並且知道資料庫的存在。 - 儲存庫類別取代了映射器類別,用於查詢資料庫,並且可能包含自訂查詢。儲存庫使用裝飾器來判斷實體屬性和資料庫資料行之間的對應。
假設資料庫中有以下 User 資料表

這是對應的實體類別的外觀
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
}
結構描述遷移工作流程
開發使用資料庫的應用程式的核心部分是變更資料庫結構描述,以適應新功能並更好地符合您正在解決的問題。在本節中,我們將討論結構描述遷移是什麼,以及它們如何影響工作流程。
由於 ORM 位於開發人員和資料庫之間,因此大多數 ORM 都提供遷移工具來協助建立和修改資料庫結構描述。
遷移是一組步驟,用於將資料庫結構描述從一種狀態轉變為另一種狀態。第一個遷移通常會建立資料表和索引。後續遷移可能會新增或移除資料行、引入新的索引或建立新的資料表。根據遷移工具的不同,遷移可能是 SQL 陳述式或程式碼的形式,這些程式碼將轉換為 SQL 陳述式(如 ActiveRecord 和 SQLAlchemy)。
由於資料庫通常包含資料,因此遷移可協助您將結構描述變更分解為較小的單元,這有助於避免意外的資料遺失。
假設您從頭開始一個專案,完整的工作流程如下所示:您建立一個遷移,它將在資料庫結構描述中建立 User 資料表,並如以上範例中定義 User 實體類別。
然後,隨著專案的進展,您決定要在 User 資料表中新增新的 salutation 資料行,您將建立另一個遷移,它將變更資料表並新增 salutation 資料行。
讓我們看看使用 TypeORM 遷移的外觀
import { MigrationInterface, QueryRunner } from 'typeorm'
export class UserRefactoring1604448000 implements MigrationInterface {
async up(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" ADD COLUMN "salutation" TEXT`)
}
async down(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" DROP COLUMN "salutation"`)
}
}
一旦執行遷移並且資料庫結構描述已變更,也必須更新實體和映射器類別,以考慮新的 salutation 資料行。
使用 TypeORM,這表示將 salutation 屬性新增至 User 實體類別
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
@Column()
salutation: string
}
同步此類變更對於 ORM 來說可能是一個挑戰,因為變更是手動套用的,並且不容易透過程式驗證。重新命名現有的資料行可能更加麻煩,並且涉及搜尋和取代對該資料行的參考。
注意: Django 的 makemigrations CLI 透過檢查模型中的變更來產生遷移,這與 Prisma ORM 類似,消除了同步問題。
總之,發展結構描述是建置應用程式的關鍵部分。使用 ORM,更新結構描述的工作流程包括使用遷移工具來建立遷移,然後更新對應的實體和映射器類別(取決於實作)。正如您將看到的,Prisma ORM 對此採取了不同的方法。
現在您已經了解了遷移是什麼以及它們如何融入開發工作流程,您將了解更多關於 ORM 的優點和缺點。
ORM 的優點
開發人員選擇使用 ORM 有不同的原因
- ORM 有助於實作網域模型。網域模型是一個物件模型,它結合了您的業務邏輯的行為和資料。換句話說,它允許您專注於實際的業務概念,而不是資料庫結構或 SQL 語意。
- ORM 有助於減少程式碼量。它們使您免於為常見的 CRUD(建立、讀取、更新、刪除)操作編寫重複的 SQL 陳述式,並逸出使用者輸入以防止諸如 SQL 注入之類的安全漏洞。
- ORM 要求您編寫很少或不編寫 SQL(取決於您的複雜性,您可能仍然需要編寫奇數原始查詢)。這對於不熟悉 SQL 但仍然想使用資料庫的開發人員來說是有益的。
- 許多 ORM 抽象化了資料庫特定的詳細資訊。從理論上講,這表示 ORM 可以使從一個資料庫變更為另一個資料庫變得更容易。應該注意的是,實際上應用程式很少變更它們使用的資料庫。
與所有旨在提高生產力的抽象化一樣,使用 ORM 也存在缺點。
ORM 的缺點
當您開始使用 ORM 時,ORM 的缺點並不總是顯而易見的。本節涵蓋了一些普遍接受的缺點
- 使用 ORM,您可以形成資料庫資料表的物件圖形表示形式,這可能會導致物件關聯阻抗失配。當您正在解決的問題形成一個複雜的物件圖形,而該圖形無法簡單地對應到關聯式資料庫時,就會發生這種情況。在兩種不同的資料表示形式(一種在關聯式資料庫中,另一種在記憶體中(使用物件))之間進行同步非常困難。這是因為與關聯式資料庫記錄相比,物件在它們彼此關聯的方式上更具彈性和多樣性。
- 雖然 ORM 處理了與問題相關的複雜性,但同步問題並沒有消失。對資料庫結構描述或資料模型的任何變更都需要將變更對應回另一側。這種負擔通常落在開發人員身上。在團隊從事專案的背景下,資料庫結構描述變更需要協調。
- 由於 ORM 封裝的複雜性,ORM 傾向於具有大型 API 介面。不必編寫 SQL 的反面是,您花費大量時間學習如何使用 ORM。這適用於大多數抽象化,但是如果不了解資料庫的工作原理,則很難改善緩慢的查詢。
- 由於 SQL 提供的彈性,某些複雜查詢不受 ORM 支援。原始 SQL 查詢功能緩解了這個問題,您可以在其中將 SQL 陳述式字串傳遞給 ORM,並且將為您執行查詢。
現在已經涵蓋了 ORM 的成本和優點,您可以更好地了解 Prisma ORM 是什麼以及它如何適應。
Prisma ORM
Prisma ORM 是下一代 ORM,它使應用程式開發人員可以輕鬆地使用資料庫,並具有以下工具
- Prisma Client:自動產生且型別安全的資料庫用戶端,可在您的應用程式中使用。
- Prisma Migrate:宣告式資料模型化和遷移工具。
- Prisma Studio:用於瀏覽和管理資料庫中資料的現代 GUI。
注意: 由於 Prisma Client 是最突出的工具,我們通常將其簡稱為 Prisma。
這三個工具都使用 Prisma schema 作為資料庫結構描述、應用程式物件結構描述以及兩者之間對應的單一事實來源。它由您定義,並且是您配置 Prisma ORM 的主要方式。
Prisma ORM 使您在建置軟體時具有生產力和信心,其功能包括型別安全、豐富的自動完成功能以及用於擷取關係的自然 API。
在下一節中,您將了解 Prisma ORM 如何實作資料映射器 ORM 模式。
Prisma ORM 如何實作資料映射器模式
如本文前面所述,資料映射器模式與資料庫和應用程式由不同團隊擁有的組織非常吻合。
隨著現代雲端環境(具有託管資料庫服務和 DevOps 實務)的興起,更多團隊採用跨職能方法,即團隊擁有包括資料庫和營運問題在內的全端開發週期。
Prisma ORM 能夠協同發展 DB 結構描述和物件結構描述,從而減少了首先出現偏差的需求,同時仍然允許您使用 @map 屬性使應用程式和資料庫在一定程度上保持分離。雖然這看起來像是一個限制,但它可以防止網域模型的發展(透過物件結構描述)在事後強加於資料庫。
為了了解 Prisma ORM 的資料映射器模式實作在概念上與傳統資料映射器 ORM 有何不同,以下是它們的概念和建構區塊的簡要比較
| 概念 | 描述 | 傳統 ORM 中的建構區塊 | Prisma ORM 中的建構區塊 | Prisma ORM 中的事實來源 |
|---|---|---|---|---|
| 物件結構描述 | 應用程式中的記憶體內資料結構 | 模型類別 | 產生的 TypeScript 類型 | Prisma schema 中的模型 |
| 資料映射器 | 在物件結構描述和資料庫之間轉換的程式碼 | 映射器類別 | Prisma Client 中產生的函式 | Prisma schema 中的 @map 屬性 |
| 資料庫結構描述 | 資料庫中資料的結構,例如,資料表和資料行 | 手動編寫或使用程式化 API 的 SQL | Prisma Migrate 產生的 SQL | Prisma schema |
Prisma ORM 符合資料映射器模式,並具有以下新增優點
- 透過根據 Prisma schema 產生 Prisma Client,減少定義類別和對應邏輯的樣板。
- 消除應用程式物件和資料庫結構描述之間的同步挑戰。
- 資料庫遷移是一流的公民,因為它們是從 Prisma schema 衍生而來的。
現在我們已經討論了 Prisma ORM 方法背後的概念,我們可以了解 Prisma schema 在實務中如何運作。
Prisma schema
Prisma 實作資料映射器模式的核心是 Prisma schema – 以下職責的單一事實來源
- 配置 Prisma 如何連線到您的資料庫。
- 產生 Prisma Client – 用於您的應用程式程式碼的型別安全 ORM。
- 使用 Prisma Migrate 建立和發展資料庫結構描述。
- 定義應用程式物件和資料庫資料行之間的對應。
Prisma ORM 中的模型與活動記錄 ORM 的模型略有不同。使用 Prisma ORM,模型在 Prisma schema 中定義為抽象實體,用於描述資料表、關係以及資料行與 Prisma Client 中屬性之間的對應。
作為範例,以下是部落格的 Prisma schema
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
以下是以上範例的分解
datasource區塊定義與資料庫的連線。generator區塊告訴 Prisma ORM 為 TypeScript 和 Node.js 產生 Prisma Client。Post和User模型對應到資料庫資料表。- 這兩個模型具有1-n 關係,其中每個
User可以有多個相關的Post。 - 模型中的每個欄位都有一個類型,例如,
id的類型為Int。 - 欄位可能包含欄位屬性以定義
- 帶有
@id屬性的主鍵。 - 帶有
@unique屬性的唯一鍵。 - 帶有
@default屬性的預設值。 - 帶有
@map屬性的資料表資料行和 Prisma Client 欄位之間的對應,例如,content欄位(在 Prisma Client 中可存取)對應到post_content資料庫資料行。
- 帶有
User / Post 關係可以使用以下圖表視覺化
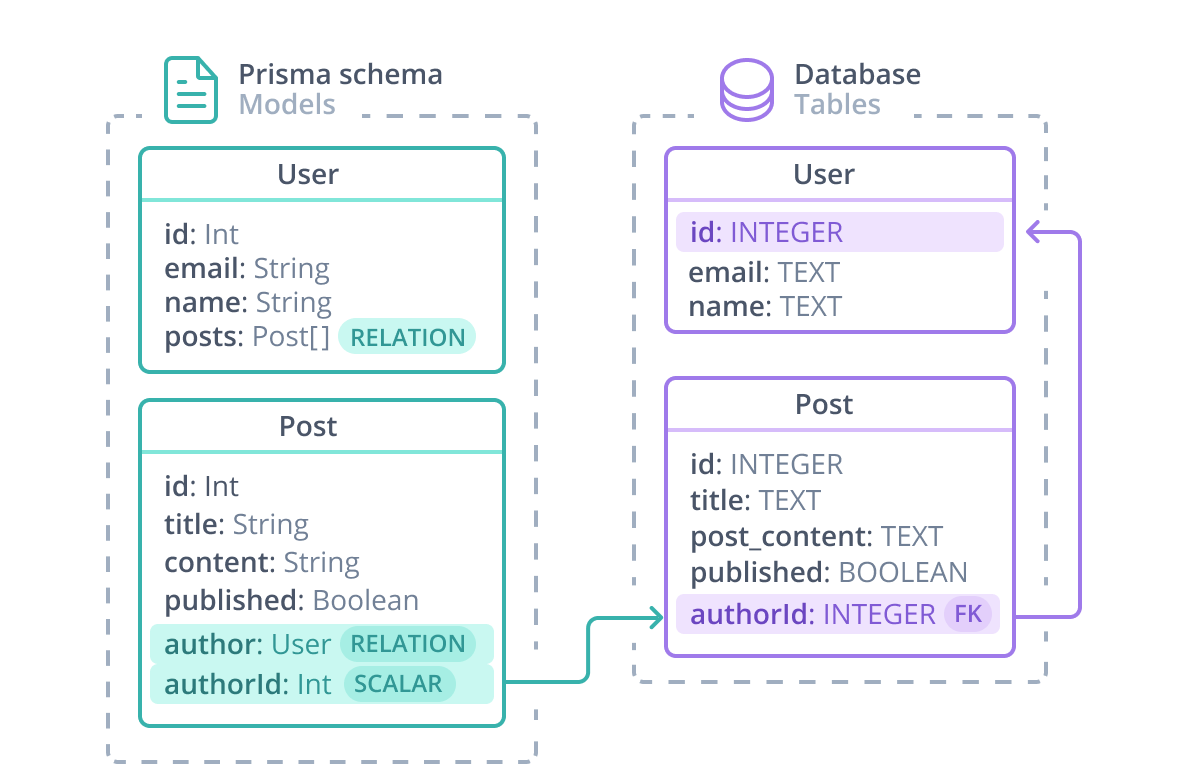
在 Prisma ORM 層級,User / Post 關係由以下組成
- 純量
authorId欄位,由@relation屬性參考。此欄位存在於資料庫資料表中 – 它是連接 Post 和 User 的外來鍵。 - 兩個關係欄位:
author和posts不存在於資料庫資料表中。關係欄位定義 Prisma ORM 層級模型之間的連線,並且僅存在於 Prisma schema 和產生的 Prisma Client 中,在其中用於存取關係。
Prisma schema 的宣告式性質簡潔明瞭,並且允許定義資料庫結構描述和 Prisma Client 中的對應表示形式。
在下一節中,您將了解 Prisma ORM 支援的工作流程。
Prisma ORM 工作流程
Prisma ORM 的工作流程與傳統 ORM 略有不同。您可以在從頭開始建置新應用程式時使用 Prisma ORM,也可以逐步採用它
- 新應用程式(綠地專案):尚無資料庫結構描述的專案可以使用 Prisma Migrate 來建立資料庫結構描述。
- 現有應用程式(棕地專案):已經有資料庫結構描述的專案可以由 Prisma ORM 自省,以產生 Prisma schema 和 Prisma Client。此使用案例適用於任何現有的遷移工具,並且適用於逐步採用。可以切換到 Prisma Migrate 作為遷移工具。但是,這是選用的。
對於這兩種工作流程,Prisma schema 都是主要組態檔。
在具有現有資料庫的專案中逐步採用的工作流程
棕地專案通常已經有一些資料庫抽象化和結構描述。Prisma ORM 可以透過自省現有資料庫來整合到此類專案中,以取得反映現有資料庫結構描述的 Prisma schema 並產生 Prisma Client。此工作流程與您可能已經使用的任何遷移工具和 ORM 相容。如果您希望逐步評估和採用,則可以使用此方法作為平行採用策略的一部分。
與此工作流程相容的非詳盡設定清單
- 使用純 SQL 檔案以及
CREATE TABLE和ALTER TABLE來建立和變更資料庫結構描述的專案。 - 使用第三方遷移程式庫(如 db-migrate 或 Umzug)的專案。
- 已經使用 ORM 的專案。在這種情況下,透過 ORM 的資料庫存取保持不變,而產生的 Prisma Client 可以逐步採用。
實際上,這些是自省現有 DB 並產生 Prisma Client 所需的步驟
- 建立
schema.prisma,定義datasource(在這種情況下,您的現有 DB)和generator
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client-js"
}
- 執行
prisma db pull以使用從您的資料庫結構描述衍生的模型來填入 Prisma schema。 - (選用)自訂 Prisma Client 和資料庫之間的欄位和模型對應。
- 執行
prisma generate。
Prisma ORM 將在 node_modules 資料夾內產生 Prisma Client,可以從您的應用程式中匯入它。如需更廣泛的使用文件,請參閱 Prisma Client API 文件。
總之,Prisma Client 可以整合到具有現有資料庫和工具的專案中,作為平行採用策略的一部分。新專案將使用下文詳述的不同工作流程。
新專案的工作流程
Prisma ORM 在其支援的工作流程方面與 ORM 不同。仔細查看建立和變更新資料庫結構描述所需的步驟,有助於了解 Prisma Migrate。
Prisma Migrate 是用於宣告式資料模型化和遷移的 CLI。與大多數作為 ORM 一部分的遷移工具不同,您只需要描述目前的結構描述,而不是從一種狀態移到另一種狀態的操作。Prisma Migrate 會推斷操作、產生 SQL 並為您執行遷移。
此範例示範如何在具有類似於上述部落格範例的新資料庫結構描述的新專案中使用 Prisma ORM
- 建立 Prisma schema
// schema.prisma
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client-js"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
- 執行
prisma migrate以產生遷移的 SQL、將其套用至資料庫,並產生 Prisma Client。
對於資料庫結構描述的任何進一步變更
- 將變更套用至 Prisma schema,例如,將
registrationDate欄位新增至User模型 - 再次執行
prisma migrate。
最後一個步驟示範了宣告式遷移如何透過將欄位新增至 Prisma schema 並使用 Prisma Migrate 將資料庫結構描述轉換為所需狀態來運作。遷移執行後,Prisma Client 會自動重新產生,以便反映更新後的結構描述。
如果您不想使用 Prisma Migrate,但仍然想在新專案中使用型別安全產生的 Prisma Client,請參閱下一節。
不使用 Prisma Migrate 的新專案的替代方案
可以在新專案中使用協力廠商遷移工具而不是 Prisma Migrate 來使用 Prisma Client。例如,新專案可以選擇使用 Node.js 遷移框架 db-migrate 來建立資料庫結構描述和遷移,並使用 Prisma Client 進行查詢。從本質上講,這包含在現有資料庫的逐步採用工作流程中。
使用 Prisma Client 存取資料
到目前為止,本文涵蓋了 Prisma ORM 背後的概念、其資料映射器模式的實作以及其支援的工作流程。在最後一節中,您將看到如何使用 Prisma Client 在您的應用程式中存取資料。
使用 Prisma Client 存取資料庫是透過其公開的查詢方法進行的。所有查詢都會傳回純舊 JavaScript 物件。給定上面的部落格結構描述,擷取使用者如下所示
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
})
在此查詢中,findUnique() 方法用於從 User 資料表擷取單列。依預設,Prisma ORM 將傳回 User 資料表中的所有純量欄位。
注意: 此範例使用 TypeScript 來充分利用 Prisma Client 提供的型別安全功能。但是,Prisma ORM 也適用於 Node.js 中的 JavaScript。
Prisma Client 透過從 Prisma schema 產生程式碼,將查詢和結果對應到結構類型。這表示 user 在產生的 Prisma Client 中具有關聯的類型
export type User = {
id: number
email: string
name: string | null
}
這確保存取不存在的欄位將引發型別錯誤。更廣泛地說,這表示每個查詢的結果類型在執行查詢之前都是已知的,這有助於捕獲錯誤。例如,以下程式碼片段將引發型別錯誤
console.log(user.lastName) // Property 'lastName' does not exist on type 'User'.
擷取關係
使用 Prisma Client 擷取關係是使用 include 選項完成的。例如,擷取使用者及其文章將如下完成
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
include: {
posts: true,
},
})
透過此查詢,user 的類型也將包含 Post,可以使用 posts 陣列欄位存取它們
console.log(user.posts[0].title)
該範例僅觸及 Prisma Client 用於 CRUD 操作的 API 的表面,您可以在文件中了解更多資訊。主要概念是所有查詢和結果都由類型支援,並且您可以完全控制關係的擷取方式。
結論
總之,Prisma ORM 是一種新型的資料映射器 ORM,它與傳統 ORM 不同,並且沒有傳統 ORM 常見的問題。
與傳統 ORM 不同,使用 Prisma ORM,您可以定義 Prisma schema – 資料庫結構描述和應用程式模型的宣告式單一事實來源。Prisma Client 中的所有查詢都會傳回純 JavaScript 物件,這使得與資料庫互動的過程更加自然且更可預測。
Prisma ORM 支援兩種主要工作流程,用於啟動新專案和在現有專案中採用。對於這兩種工作流程,您的主要配置途徑都是透過 Prisma schema。
與所有抽象化一樣,Prisma ORM 和其他 ORM 都以不同的假設隱藏了資料庫的一些底層詳細資訊。
這些差異和您的使用案例都會影響工作流程和採用成本。希望了解它們的差異可以幫助您做出明智的決定。