

從 SQL 資料庫中的多個表格提取相關資料可能會變得非常耗費資源。Prisma ORM 現在讓您可以在資料庫層級和應用程式層級的 Join 之間做選擇,以便您可以為您的關聯查詢選擇效能最佳的方法。

目錄
Prisma ORM 新功能:選擇最佳的 Join 策略 🎉
支援資料庫層級的 Join 一直是 Prisma ORM 中最受歡迎的功能之一,我們很高興分享這項功能現在已作為另一種查詢策略提供! 
對於任何使用 include (或 select) 的關聯查詢,現在在頂層有一個稱為 relationLoadStrategy 的新選項。此選項接受兩個可能值之一
join(預設):使用資料庫層級的 Join 策略來合併資料庫中的資料。query:使用應用程式層級的 Join 策略,透過傳送多個查詢到個別表格,並在應用程式層合併資料。
若要啟用新的 relationLoadStrategy,您首先需要將預覽功能標誌新增至 Prisma Client 的 generator 區塊
注意:
relationLoadStrategy僅適用於 PostgreSQL 和 MySQL 資料庫。
完成後,您需要重新執行 prisma generate,此變更才會生效,並在您的查詢中選擇關聯載入策略。
以下範例使用新的 join 策略
請注意,由於 "join" 是預設值,因此在上面的程式碼片段中,技術上也可以省略 relationLoadStrategy 選項。我們在這裡展示它只是為了說明目的。
join vs query — 何時使用哪個?
現在有了這兩種查詢策略,您可能會想知道:何時使用哪個?
由於 Prisma ORM 在 PostgreSQL 上使用橫向、彙總的 JOIN,以及在 MySQL 上使用相關子查詢,因此 join 策略在大多數情況下可能更有效率(稍後章節將有更多關於此的詳細資訊)。資料庫引擎非常強大,並且非常擅長最佳化查詢計畫。這個新的關聯載入策略正是對此致敬。
但是,在某些情況下,您可能仍然希望使用 query 策略來針對每個表格執行一個查詢,並在應用程式層級合併資料。根據資料集和在 schema 中設定的索引,傳送多個查詢可能會更有效能。分析和基準測試您的查詢對於找出這些情況至關重要。
另一個考量可能是複雜的 Join 查詢所造成的資料庫負載。如果由於某些原因,資料庫伺服器上的資源稀缺,您可能會希望將複雜的 Join 查詢與篩選和分頁所需的大量運算移至您的應用程式伺服器,這可能更容易擴展。
TLDR
- 新的
join策略在大多數情況下會更有效率。 - 在某些邊緣情況下,根據資料集和查詢的特性,
query可能會更有效能。我們建議您分析您的資料庫查詢,以找出這些情況。 - 如果您想要節省資料庫伺服器上的資源,並在應用程式伺服器中進行大量合併和轉換資料的工作,而應用程式伺服器可能更容易擴展,請使用
query。
了解 SQL 資料庫中的關聯
現在我們了解了 Prisma ORM 的 JOIN 策略,讓我們回顧一下關聯查詢在 SQL 資料庫中通常是如何運作的。
關聯的扁平與巢狀資料結構
SQL 資料庫以扁平(即 正規化)的方式儲存資料。實體之間的關聯透過外鍵表示,外鍵指定跨表格的參考。
另一方面,應用程式開發人員通常習慣使用巢狀資料,即可以任意深度巢狀其他物件的物件。
這是一個巨大的差異,不僅在資料實體在磁碟和記憶體上的佈局方式,而且在於心智模型和資料推理方面。
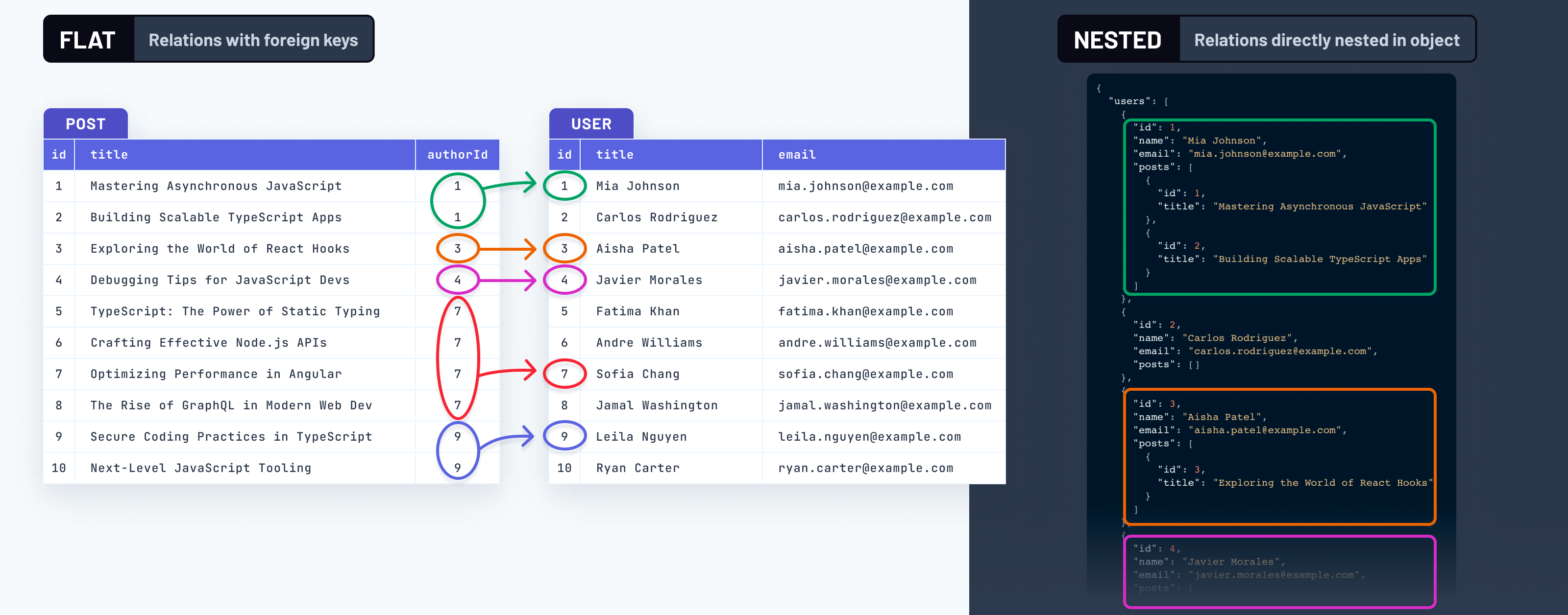
關聯資料需要為應用程式開發人員「合併」
由於相關資料在資料庫中以實體方式分開儲存,因此需要將其合併到某個地方,才能成為應用程式開發人員熟悉的巢狀結構。此合併也稱為「join」。
有兩個地方可以發生此 join
- 在資料庫層級:將單一 SQL 查詢傳送到資料庫。查詢使用
JOIN關鍵字或相關子查詢,讓資料庫執行跨多個表格的 join,並傳回巢狀結構。 - 在應用程式層級:將多個查詢傳送到資料庫。每個查詢僅存取單一表格,然後在應用程式層的記憶體中合併查詢結果。這曾經是
v5.9.0之前 Prisma Client 唯一支援的查詢策略。
哪種方法更理想取決於使用的資料庫、資料集的大小和特性以及查詢的複雜性。繼續閱讀以了解何時建議使用哪種策略。
底層發生了什麼事?
Prisma ORM 使用 PostgreSQL 中的 LATERAL join 和資料庫層級 JSON 聚合(例如透過 json_agg),以及 MySQL 上的相關子查詢,實作了新的 join 關聯載入策略。
在以下章節中,我們將探討為什麼 PostgreSQL 上的 LATERAL join 和資料庫層級 JSON 聚合方法比普通的傳統 JOIN 更有效率。
透過 JSON 聚合防止查詢結果中的冗餘
當使用資料庫層級 JOIN 時,有幾種選項可用於建構 SQL 查詢。讓我們考慮上面 Prisma schema 的 SQL 表格定義
若要檢索所有使用者及其貼文,您可以使用簡單的 LEFT JOIN 查詢
以下是使用一些範例資料的結果範例
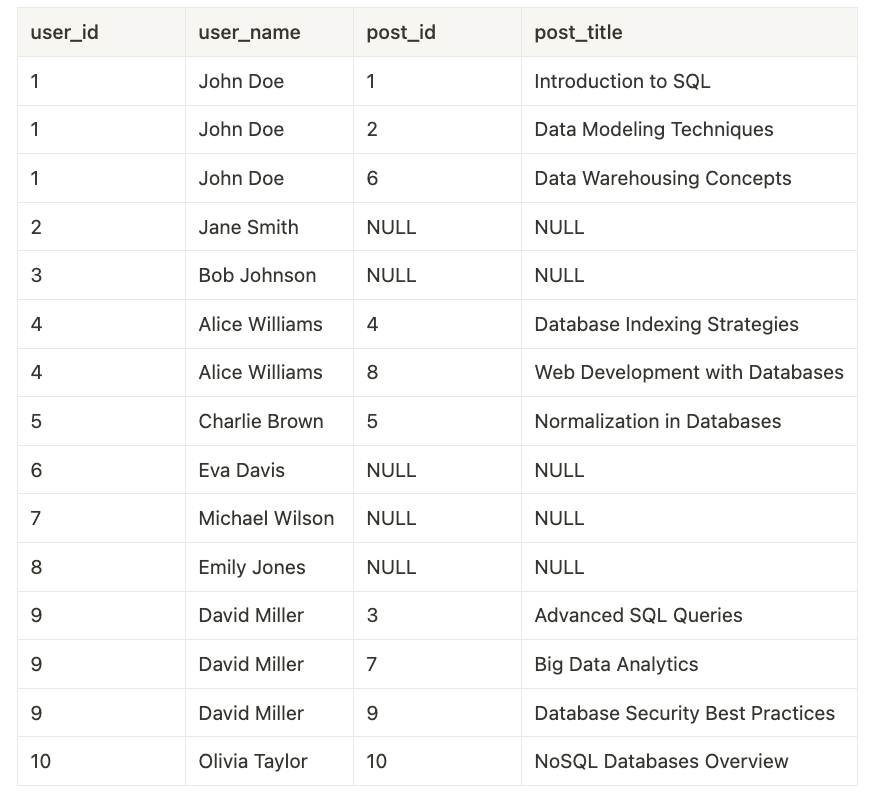
請注意此案例中 user_name 欄位中的冗餘。當 join 的表格越多,這種冗餘只會變得更糟。例如,假設還有另一個 Comment 表格,其中每個註解都有一個 postId 外鍵,指向 Post 表格中的記錄。
以下是用於表示該內容的 SQL 查詢
現在,假設第一篇貼文有多個註解
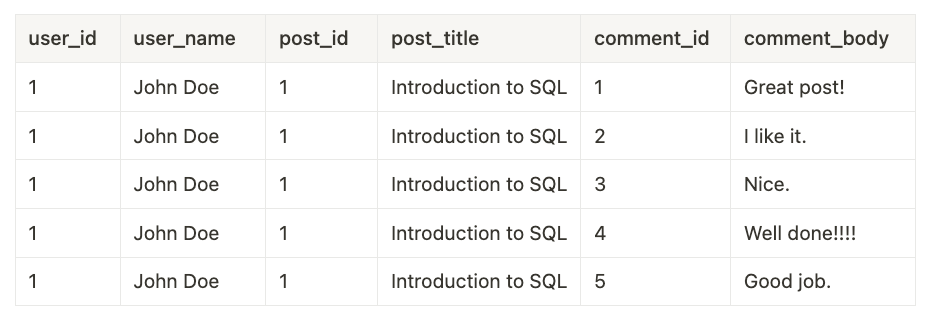
在這種情況下,結果集的大小會隨著 join 的表格數量呈指數成長。由於此資料會透過網路從資料庫傳輸到應用程式伺服器,因此可能會變得非常耗費資源。
Prisma 實作的 join 策略,透過資料庫層級的 JSON 聚合解決了這個問題。
以下是 PostgreSQL 的範例,它使用 json_agg 和 json_build_object 來解決冗餘問題,並以 JSON 格式傳回每個使用者的貼文
這次的結果集不包含冗餘資料。此外,資料結構方便地已經具有 Prisma Client 傳回的形狀,這省去了在查詢引擎中轉換結果的額外工作

用於更有效率的查詢與分頁和篩選的橫向 JOIN
關聯查詢(與大多數其他查詢一樣)幾乎從不提取表格中的所有資料,而是帶有其他結果集限制,例如篩選和分頁。特別是分頁在使用傳統 JOIN 時可能會變得非常複雜,讓我們看看另一個範例。
考慮這個 Prisma Client 查詢,它提取 10 個使用者和每個使用者 5 篇貼文
當以原始 SQL 撰寫此查詢時,您可能會想要在子查詢內使用 LIMIT 子句,例如
但是,這將無法運作,因為內部 SELECT 實際上並未傳回每個使用者的五篇貼文 — 而是傳回總共兩篇貼文,這當然完全不是所需的結果。
使用傳統 JOIN,這可以透過使用 row_number() 函數來解決,該函數將遞增整數指派給結果集中的記錄,藉此可以手動執行分頁的計算。
儘管如此,這種方法很快就會變得非常複雜,因此不適合建置分頁關聯查詢。
維護、擴展和偵錯這些種類的 SQL 查詢既令人氣餒,又可能消耗數小時的開發時間。
值得慶幸的是,較新的資料庫版本透過一種新型查詢解決了這個問題:橫向 JOIN。
上面的查詢可以使用 LATERAL 關鍵字簡化
這不僅使查詢更易於閱讀,而且資料庫引擎也可能更能夠最佳化查詢,因為它可以更了解查詢的意圖。
結論
讓我們回顧一下使用 Prisma 進行關聯查詢的資料 join 的不同選項。
過去,Prisma 僅支援應用程式層級的 Join 策略,該策略會將多個查詢傳送到資料庫,並在查詢引擎內部完成所有合併和轉換為預期 JavaScript 物件結構的工作
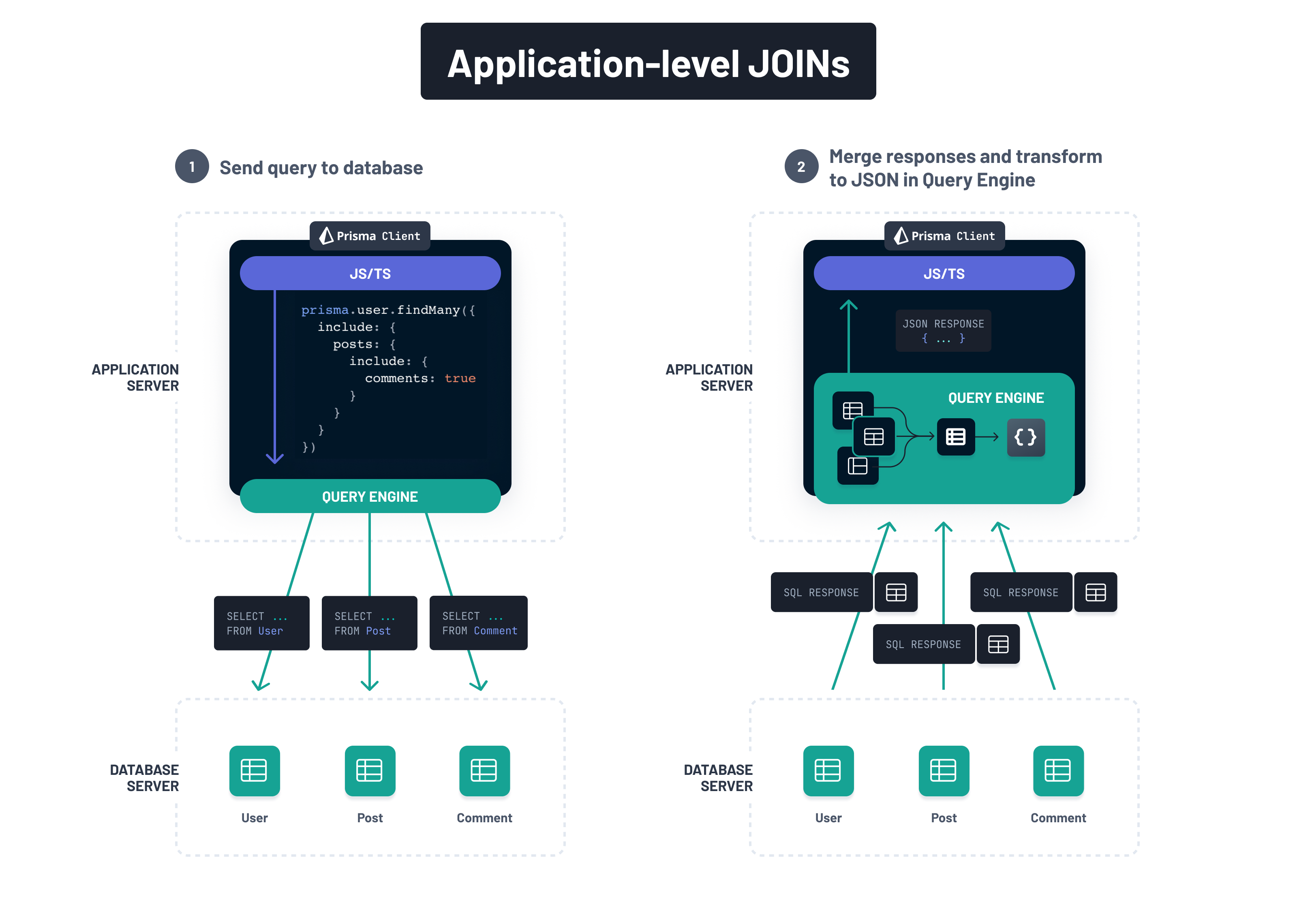
使用普通的傳統 JOIN,資料的合併將委派給資料庫。但是,如上所述,資料冗餘(結果集隨著關聯查詢中表格的數量呈指數成長)以及包含篩選和分頁的查詢的複雜性存在問題
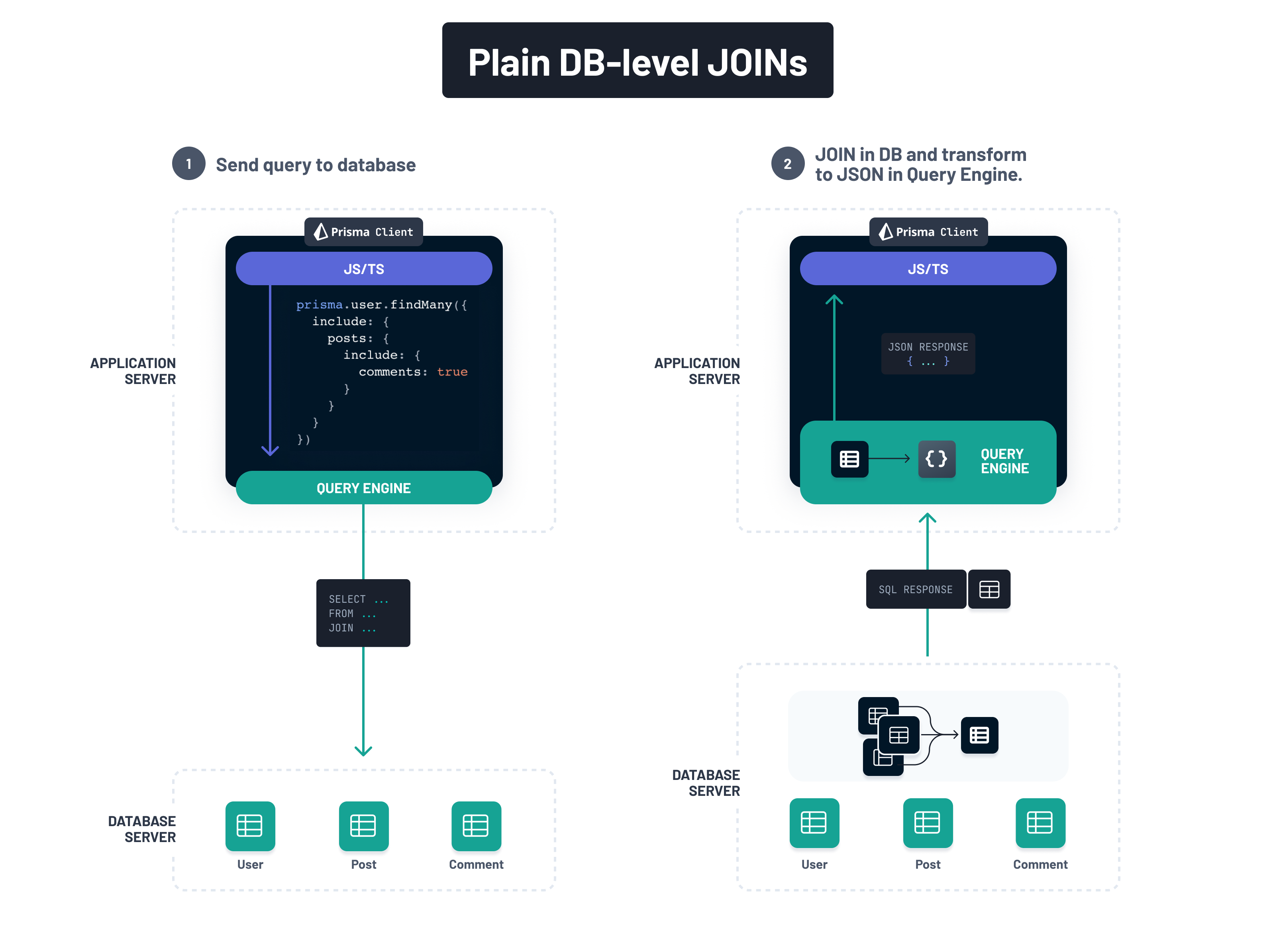
為了解決這些問題,Prisma ORM 實作了現代化的橫向 JOIN,並在資料庫層級伴隨 JSON 聚合。這樣,解決查詢並將資料帶入預期的 JavaScript 物件結構所需的所有繁重工作都在資料庫層級完成

試用並分享您的回饋
我們很樂意讓您試用新的關聯查詢載入策略。請告訴我們您的想法,並與我們分享您的回饋!
不要錯過下一篇文章!
註冊 Prisma 電子報